Definición de Estadística
La Estadística trata del recuento, ordenación y clasificación de los datos obtenidos por las observaciones, para poder hacer comparaciones y sacar conclusiones.
Un estudio estadístico consta de las siguientes fases:
1º Recogida de datos
2º Organización y representación de datos
3º Análisis de datos
4º Obtención de conclusiones
Conceptos de Estadística
Población
Una población es el conjunto de todos los elementos a los que se somete a un estudio estadístico.
Ejemplo: El conjunto de los ciudadanos españoles.
Individuo
Un individuo o unidad estadística es cada uno de los elementos que componen la población.
Ejemplo: Un ciudadano español.
Muestra
Una muestra es un conjunto representativo de la población de referencia, el número de individuos de una muestra es menor que el de la población.
Ejemplo: Ciudadanos españoles mayores de edad.
Muestreo
El muestreo es la reunión de datos que se desea estudiar, obtenidos de una proporción reducida y representativa de la población.
Valor
Un valor es cada uno de los distintos resultados que se pueden obtener en un estudio estadístico.
Ejemplo: Si lanzamos una moneda al aire  veces obtenemos dos valores: cara y cruz.
veces obtenemos dos valores: cara y cruz.
Dato
Un dato es cada uno de los valores que se ha obtenido al realizar un estudio estadístico.
Ejemplo: Si lanzamos una moneda al aire veces obtenemos datos: cara, cara, cruz, cara, cruz.
Variables estadísticas
¿Qué es una variable estadística?
Una variable estadística es cada una de las características o cualidades que poseen los individuos de una población.
Tipos de variable estadísticas
Variables cualitativas
Las variables cualitativas se refieren a características o cualidades que no pueden ser medidas con números. Podemos distinguir dos tipos:
1º Variable cualitativa nominal
Una variable cualitativa nominal presenta modalidades no numéricas que no admiten un criterio de orden.
Ejemplo:
El estado civil, con las siguientes modalidades: soltero, casado, separado, divorciado y viudo.
2º Variable cualitativa ordinal o variable cuasicuantitativa
Una variable cualitativa ordinal presenta modalidades no numéricas, en las que existe un orden.
Ejemplos:
- La nota en un examen: suspenso, aprobado, notable, sobresaliente.
- Puesto conseguido en una prueba deportiva: primero, segundo, tercer, …
- Medallas de una prueba deportiva: oro, plata, bronce.
Variables cuantitativas
Una variable cuantitativa es la que se expresa mediante un número, por tanto se pueden realizar operaciones aritméticas con ella. Podemos distinguir dos tipos:
1º Variable discreta
Una variable discreta es aquella que solo puede tomar un número finito de valores entre dos valores cualesquiera de una característica.
Ejemplo:
El número de hermanos de amigos:  .
.
2º Variable continua
Una variable continua es aquella que puede tomar un número infinito de valores entre dos valores cualesquiera de una característica.
Ejemplos:
La altura de los amigos: 
Construcción de tablas de frecuencia
Definición de distribución de frecuencias
La distribución de frecuencias o tabla de frecuencias es una ordenación en forma de tabla de los datos estadísticos, asignando a cada dato su frecuencia correspondiente.
Frecuencia absoluta
La frecuencia absoluta es el número de veces que aparece un determinado valor en un estudio estadístico.
Al tirar una moneda  veces salen
veces salen  caras
caras
Se representa por  , aunque otros autores la representan como
, aunque otros autores la representan como  .
.


La suma de las frecuencias absolutas es igual al número total de datos, que se representa por  .
.


Para indicar resumidamente estas sumas se utiliza la letra griega (sigma mayúscula) que se lee suma o sumatoria.

Frecuencia relativa
La frecuencia relativa es el cociente entre la frecuencia absoluta de un determinado valor y el número total de datos.
Se puede expresar en tanto por ciento y se representa por .

La frecuencia relativa es un número comprendido entre  y
y  .
.
La suma de las frecuencias relativas es igual a .



Frecuencia acumulada
La frecuencia acumulada es la suma de las frecuencias absolutas de todos los valores inferiores o iguales al valor considerado.
Se representa por  .
.
Frecuencia relativa acumulada
La frecuencia relativa acumulada es el cociente entre la frecuencia acumulada de un determinado valor y el número total de datos.
Se puede expresar en tantos por ciento.
Ejemplo:
Durante el mes de julio, en una ciudad se han registrado las siguientes temperaturas máximas:

 .
.
En la primera columna de la tabla colocamos la variable ordenada de menor a mayor
En la segunda hacemos el recuento
En la tercera anotamos la frecuencia absoluta
En la cuarta anotamos la frecuencia acumulada:
En la primera casilla colocamos la primera frecuencia absoluta:
En la segunda casilla sumamos el valor de la frecuencia acumulada anterior más la frecuencia absoluta correspondiente:

En la tercera casilla sumamos el valor de la frecuencia acumulada anterior más la frecuencia absoluta correspondiente:

La última tiene que ser igual a (sumatoria de ).

En la quinta columna disponemos las frecuencias relativas  que son el resultado de dividir cada frecuencia absoluta por
que son el resultado de dividir cada frecuencia absoluta por 
En la sexta anotamos la frecuencia relativa acumulada  .
.
En la primera casilla colocamos la primera frecuencia relativa acumulada.
En la segunda casilla sumamos el valor de la frecuencia relativa acumulada anterior más la frecuencia relativa correspondiente y así sucesivamente hasta la última, que tiene que ser igual a .
 | Recuento | | | | |
|---|---|---|---|---|---|
 | I | | |  | |
 | II |  |  |  |  |
 | 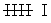 |  |  |  |  |
 | 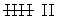 |  |  |  |  |
 | 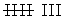 |  |  |  |  |
 | III | | | |  |
 | III | | | |  |
 | I | | | | |
| |
Este tipo de tablas de frecuencias se utiliza con variables discretas.
Distribución de frecuencias agrupadas
La distribución de frecuencias agrupadas o tabla con datos agrupados se emplea si las variables toman un número grande de valores o la variable es continua.
Se agrupan los valores en intervalos que tengan la misma amplitud denominados clases. A cada clase se le asigna su frecuencia correspondiente.
Límites de la clase
Cada clase está delimitada por el límite inferior de la clase y el límite superior de la clase.
Amplitud de la clase
La amplitud de la clase es la diferencia entre el límite superior e inferior de la clase.
Marca de clase
La marca de clase es el punto medio de cada intervalo y es el valor que representa a todo el intervalo para el cálculo de algunos parámetros.
La marca de clase se representa por 

Construcción de una tabla de datos agrupados

1º Se localizan los valores menor y mayor de la distribución. En este caso son y  .
.
2º Se restan y se busca un número entero un poco mayor que la diferencia y que sea
divisible por el número de intervalos queramos establecer.
Es conveniente que el número de intervalos oscile entre y  .
.
En este caso,  , incrementamos el número hasta ,
, incrementamos el número hasta ,  intervalos.
intervalos.
Se forman los intervalos teniendo presente que el límite inferior de una clase pertenece al intervalo, pero el límite superior no pertenece intervalo, se cuenta en el siguiente intervalo.
es la marca de clase que es el punto medio de cada intervalo.
| | | | | |
|---|---|---|---|---|---|
 |  | | |  | |
 |  | | | |  |
 |  | | |  |  |
 |  | | | |  |
 |  | |  | |  |
 |  | |  |  |  |
 |  | | |  |  |
 |  |  | |  |  |
 |  |  |  |  |  |
 |  | |  | | |
| 1 |
Diagrama de barras y polígonos de frecuencias
Diagrama de barras
Un diagrama de barras se utiliza para representar datos cualitativos o datos cuantitativos de tipo discreto.
Se representan sobre unos ejes de coordenadas, en el eje de abscisas se colocan los valores de la variable, y sobre el eje de ordenadas las frecuencias absolutas o relativas o acumuladas.
Los datos se representan mediante barras de una altura proporcional a la frecuencia.
Ejemplo:
Un estudio hecho al conjunto de los 20 alumnos de una clase para determinar su grupo sanguíneo ha dado el siguiente resultado:
| Grupo sanguíneo | fi |
|---|---|
| A | 6 |
| B | 4 |
| AB | 1 |
| 0 | 9 |
| 20 |
Representa lo anterior mediante un diagrama de barras.
1º En el eje de las abscisas colocamos los elemento del grupo sanguíneo y en el eje de las ordenadas la frecuencias de cada elemento.
2º Representamos cada elemento del grupo sanguíneo con una barra. Todas las barras deben tener el mismo ancho.
3º Obtenemos la siguiente gráfica

Polígonos de frecuencia
Un polígono de frecuencias se forma uniendo los extremos de las barras mediante segmentos.
También se puede realizar trazando los puntos que representan las frecuencias y uniéndolos mediante segmentos.
Ejemplo:
Las temperaturas en un día de otoño de una ciudad han sufrido las siguientes variaciones:
| Hora | Temperatura |
|---|---|
| 6 | 7º |
| 9 | 12° |
| 12 | 14° |
| 15 | 11° |
| 18 | 12° |
| 21 | 10° |
| 24 | 8° |
Representa lo anterior mediante un polígono de frecuencias.
1º En el eje de las abscisas colocamos las horas y en el eje de las ordenadas las temperaturas.
2º Trazamos para cada hora de la tabla su respectiva frecuencia.
3º Obtenemos la siguiente gráfica

Como hacer un diagrama de sectores
En un diagrama de sectores los datos se representan en un círculo dividido en sectores, de modo que el ángulo de cada sector es proporcional a la frecuencia absoluta correspondiente.

El diagrama de sectores se construye con la ayuda de un transportador de ángulos.
Un diagrama de sectores se puede utilizar para todo tipo de variables, pero se usa frecuentemente para las variables cualitativas.
Ejemplo:
En una clase de alumnos,  juegan a baloncesto, practican la natación, juegan al fútbol y el resto no practica ningún deporte.Representar los datos en un diagrama de vectores.
juegan a baloncesto, practican la natación, juegan al fútbol y el resto no practica ningún deporte.Representar los datos en un diagrama de vectores.
1º Calculamos el ángulo correspondiente aplicando regla de tres directa
| Alumnos | Ángulo | |
|---|---|---|
| Baloncesto | |  |
| Natación | |  |
| Fútbol | |  |
| Sin deporte | |  |
| Total | |  |
2º Representamos los sectores con sus ángulos correspondientes

El histograma
¿Qué es un histograma?
Un histograma es la representación gráfica en forma de barras, que simboliza la distribución de un conjunto de datos. Sirven para obtener una «primera vista» general, o panorama, de la distribución de la población, o de la muestra, respecto a una característica, cuantitativa y continua.

En un histograma el eje de las  (o abscisas) consiste del rango en el cual se encuentran los datos. Ahora, las bases de los rectángulos consisten de los intervalos en los cuales agrupamos dichos datos.
(o abscisas) consiste del rango en el cual se encuentran los datos. Ahora, las bases de los rectángulos consisten de los intervalos en los cuales agrupamos dichos datos.
Por otro lado, en el eje de las  (u ordenadas) tenemos más opciones, dependiendo estas opciones es el tipo de histograma que tenemos. Los dos tipos principales de histogramas son los siguientes:
(u ordenadas) tenemos más opciones, dependiendo estas opciones es el tipo de histograma que tenemos. Los dos tipos principales de histogramas son los siguientes:
- Histograma de frecuencias absolutas. Representa la frecuencia absoluta mediante la altura de las barras.
- Histograma de frecuencias relativas.Representa la frecuencia relativa mediante la altura de las barras.
Así, ya que conocemos las características de un histograma, tenemos que para construir uno, dado un conjunto de datos, debemos seguir los siguientes pasos.
- Dibujamos el eje de las abscisas de tal forma que incluya como mínimo el rango de los datos y, posteriormente, dividimos este rango en los intervalos dados.
- Dibujamos el eje de las ordenadas representando las frecuencias absolutas o relativas según sea el caso.
- Se dibujan los rectángulos de anchura igual y proporcional al intervalo (en nuestro caso todos tendrán la misma anchura) y de altura igual a la frecuencia absoluta o relativa, según sea el caso.
Ejemplo. Consideremos los siguientes datos
| Edad | Personas |
|---|---|
 | |
 |  |
 |  |
 | |
 | |
 | |
 | |
 | |
 | |
![[90, 100]](https://www.superprof.es/apuntes/wp-content/ql-cache/quicklatex.com-ae040ea91247788119d32a858e6b0936_l3.png) | |
| Total: |  |
Nuestro histograma de frecuencias absolutas sería el siguiente

Por otro lado, nuestro histograma de frecuencias relativas sería el siguiente
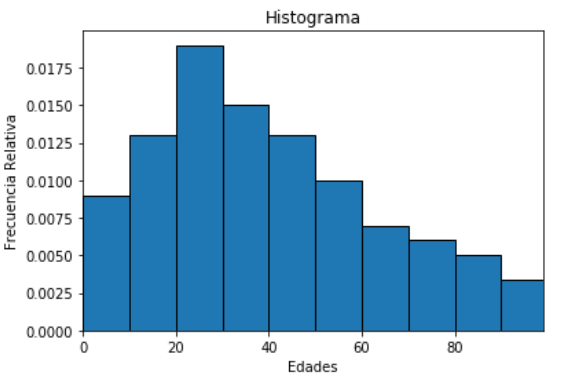
Polígono de frecuencia
Un polígono de frecuencias da la misma información de un histograma, para esto graficamos un punto por cada clase del conjunto de datos en donde en la entrada de las abscisas se toma el valor del punto medio de la clase y en la entrada las ordenadas tendrán en mismo valor que la altura del rectángulo. Al final, unimos cada punto con su sucesor y su antecesor.
Ejemplo. Utilizando el mismo conjunto de datos del ejemplo anterior
| Edad | Personas () | Frecuencia Acumulada () | |
|---|---|---|---|
| | | |
| |  | |
| |  |  |
| |  | |
| |  |  |
| |  |  |
| |  |  |
| |  |  |
| |  |  |
| | |  |
| Total: | |

Histograma y polígono de frecuencias acumuladas
Si se representan las frecuencias acumuladas de una tabla de datos agrupados se obtiene el histograma de frecuencias acumuladas y su correspondiente polígono.
Ejemplo. Utilizando el mismo conjunto de datos del ejemplo anterior
| Edad | Personas () | Frecuencia Acumulada () | |
|---|---|---|---|
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| Total: | |

Histogramas con intervalos de amplitud diferente
En este caso, el histograma debería representar la frecuencia de cada intervalo con el área de la barra y no con su altura. Por lo tanto, calculamos la altura de cada barra de la siguiente manera

En donde
 es la altura del intervalo
es la altura del intervalo- es la frecuencia absoluta o relativa del intervalo, según sea el caso.
 es la amplitud del intervalo
es la amplitud del intervalo
La idea del polígono de frecuencias sigue siendo exactamente la misma.
Ejemplo. Consideremos una agrupación distinta de los datos de los ejemplos anteriores
| Edad | | Personas () | Frecuencia relativa ( ) ) | relativa. |
|---|---|---|---|---|
| | |  |  |
| | |  |  |
| | |  |  |
 | | |  |  |
| | |  |  |
| | |  |  |
| | |  |  |
| | |  |  |
| Total: | | |
Su histograma y su polígono de frecuencias relativas sería el siguiente

Parámetros estadísticos descriptivos
Un parámetro estadístico es un número que se obtiene a partir de los datos de una muestra estadística. Los parámetros estadísticos también se conocen como estadísticos descriptivos.
Los parámetros estadísticos sirven para sintetizar o resumir la información dada por una tabla o por una gráfica. En otras palabras, dados unos pocos parámetros estadísticos se puede tener una idea general de la distribución de la información.
Los parámetros estadísticos dan un buen resumen cuando se conoce la distribución de la población. En particular, si la muestra proviene de una distribución normal, entonces el promedio típico y la desviación estándar dan un buen resumen de la distribución.
Ejemplos de parámetros estadísticos son el promedio, la mediana, la desviación estándar o los cuartiles.
Los parámetros estadísticos se clasifican según la información que resumen. Los dos tipos más comunes de parámetros estadísticos son:
- De tendencia central
- De dispersión
Otros tipo de parámetros estadísticos son aquellos de forma y escala. Estos parámetros son más utilizados en distribuciones como la Beta, Pareto o Weibull —por lo tanto, no las describiremos ya que nos enfocamos principalmente en la distribución normal—.
Medidas de tendencia central
Estos parámetros nos indican alrededor de qué valor (centro) se distribuyen los datos.
Algunas medidas de tendencia central son (al dar clic en el enlace podrás ver una descripción detallada de cada parámetro):
Media aritmética:
La media es el valor promedio de la muestra. También se puede interpretar como el centro de gravedad de los datos.
Mediana:
La mediana es el valor que separa la mitad superior de la muestra y la inferior. En otras palabras, divide los datos en dos partes iguales.
Moda:
La moda es el valor que más se repite en una muestra. Es decir, es el valor más frecuente.
Ejemplo
Tenemos los siguientes datos, los cuales representan las edades en una oficina:

Para estos datos:
1º Su media es 29.92 años. Es decir, el trabajador promedio tiene 30 años (después de redondear).
2º La moda de estos datos es 27 años. Por lo tanto, 27 años es la edad más frecuente.
3º La mediana es 27 años también. Esto significa que la mitad de los empleados tienen más de 27 años, mientras que la otra mitad tienen 27 años o menos.
Podemos observar los datos en la siguiente gráfica:

Medidas de dispersión
Las medidas de dispersión nos informan sobre cuánto se alejan del centro los valores de la distribución. Es decir, son un resumen sobre qué tan dispersos están los datos.
Algunas medidas de dispersión son:
Rango o recorrido:
El rango es la diferencia entre el mayor y el menor de los valores de una muestra. Este valor nos indica en qué rango se encuentran los datos.
Desviación media:
La desviación media es la media de los valores absolutos de las desviaciones respecto a la media. En otras palabras, es el promedio de cuánto se desvían los datos de la media (en valor absoluto).
Varianza:
La varianza es el promedio del cuadrado de las desviaciones respecto a la media. O sea, mide el promedio de cuánto se desvían los datos al cuadrado —primero elevamos al cuadrado y luego calculamos el promedio—.
Desviación estándar:
La desviación estándar es la raíz cuadrada de la varianza. Este suele ser un mejor estimador que la desviación media cuando tratamos con la distribución normal.
Cuantiles:
Los cuantiles dividen una muestra en  partes iguales. Estos nos ayudan a tener una idea de los rangos en los que se concentran más valores.
partes iguales. Estos nos ayudan a tener una idea de los rangos en los que se concentran más valores.
Dependiendo el valor de , los cuartiles pueden tener nombres particulares:
- Cuartiles: Estos dividen los datos en cuatro partes iguales.
- Deciles: Los deciles dividen la muestra en diez conjuntos del mismo tamaño.
- Percentiles: Los percentiles dividen los datos en cien partes iguales.
Ejemplo
Con los mismos datos del ejemplo anterior —edades de los empleados de una oficina—:
La medidas de dispersión de estos datos son:
1º Su rango es 22 años. Es decir, entre el trabajador más joven y el empleado más grande hay 22 años de diferencia.
2º Su desviación media es 5.44 años. Esto es, los empleados suelen estar 5 años más jóvenes o más viejos que la media —esta desviación es promedio, por lo tanto, algunos empleados se desvían más de 5 años y otros se desvían menos de 5 años—.
3º La varianza 41.61 años.
4º La desviación estándar es de 6.45 años.
5º Por último, la muestra tiene solo 13 individuos. Por este motivo, no es apropiado utilizar deciles o percentiles. Sin embargo, podemos calcular los cuartiles:
- Primer cuartil: 26 años.
- Segundo cuartil: 27 años.
- Tercer cuartil: 34 años.
De esta manera, podemos interpretar que aproximadamente el 25% de los empleados tienen menos de 26 años. Además, hay muchos empleados entre 26 y 27 años (casi el 25% de los empleados tienen esas edades, pues están entre el primer y segundo cuartil). Por último, sólo el 25% de los trabajadores tienen más de 34 años —que es equivalente a decir que aproximadamente el 75% de los trabajadores son menores de 34 años—.
Moda estadística
Definición de moda estadística
- La moda es el valor que tiene mayor frecuencia absoluta.
- Se representa por
 .
. - Si en un grupo hay dos o varias puntuaciones con la misma frecuencia y esa frecuencia es la máxima, entonces la distribución es bimodal (en caso de que sean valores) o multimodal (en caso de que existan mas de ), es decir, tiene varias modas.
- Cuando todas las puntuaciones de un grupo tienen la misma frecuencia, no hay moda.
- Se puede hallar la moda para variables cualitativas y cuantitativas.
- Cuando todas las puntuaciones de un grupo tienen la misma frecuencia, no hay moda.
- Si dos puntuaciones adyacentes tienen la frecuencia máxima, la moda es el promedio de las dos puntuaciones adyacentes.
- Si dos puntuaciones adyacentes tienen la frecuencia máxima, la moda es el promedio de las dos puntuaciones adyacentes.Ejemplos de ejercicios de moda
Ejemplos de cálculo de la moda
1º Hallar la moda de la distribución: 

2º Hallar la moda de la distribución:

3º Hallar la moda de la distribución: 
Como todas las puntuaciones del grupo tienen la misma frecuencia, no hay moda.
4º Hallar la moda de la distribución: 

Cálculo de la moda para datos agrupados
Caso 1: Cuando todos los intervalos tienen la misma amplitud.

 es el límite inferior de la clase modal
es el límite inferior de la clase modal- es la frecuencia absoluta de la clase modal
 es la frecuencia absoluta inmediatamente inferior a la clase modal
es la frecuencia absoluta inmediatamente inferior a la clase modal es la frecuencia absoluta inmediatamente posterior a la clase modal
es la frecuencia absoluta inmediatamente posterior a la clase modal- es la amplitud de la clase
También se utiliza otra fórmula de la moda que da un valor aproximado de ésta:

Ejemplo:
Calcular la moda de una distribución estadística que viene dada por la siguiente tabla:
| |
|---|---|
 | |
 |  |
 |  |
 | |
 | |
|
En primer lugar buscamos el intervalo donde se encuentra la moda, que será el intervalo que tenga la mayor frecuencia absoluta  .
.
La clase modal es:
Aplicaremos la fórmula para el cálculo de la moda para datos agrupados, extrayendo los siguientes datos:
Límite inferior: 






Caso 2: Cuando los intervalos tienen amplitudes distintas.
1º En primer lugar tenemos que hallar las alturas.

2º La clase modal es la que tiene mayor altura.

3º La fórmula de la moda aproximada cuando existen distintas amplitudes es:

Ejemplo:
En la siguiente tabla se muestra las calificaciones (suspenso, aprobado, notable y sobresaliente) obtenidas por un grupo de 50 alumnos. Calcular la moda.
| |
|---|---|
| |
 |  |
 | |
 | |
En primer lugar creamos una nueva columna con las alturas, dividiendo las frecuencias absolutas entre las amplitudes de los intervalos correspondientes:


| | |
|---|---|---|
| | |
| | |
| | |
| | |
|
La clase modal es porque es la que tiene mayor altura
Limite inferior:






La mediana
¿Qué es la mediana?
La mediana es el valor que ocupa el lugar central de todos los datos cuando éstos están ordenados de menor a mayor.
La mediana se representa por 
La mediana se puede hallar solo para variables cuantitativas.
Ejemplo de cálculo simple de la mediana
1º Ordenamos los datos de menor a mayor.
2º Si la serie tiene un número impar de medidas la mediana es la puntuación central de la misma


3º Si la serie tiene un número par de puntuaciones la mediana es la media entre las dos puntuaciones centrales.


Fórmula y cálculo de la mediana para datos agrupados
La mediana se encuentra en el intervalo donde la frecuencia acumulada llega hasta la mitad de la suma de las frecuencias absolutas.
Es decir tenemos que buscar el intervalo en el que se encuentre.

 es el límite inferior de la clase donde se encuentra la mediana
es el límite inferior de la clase donde se encuentra la mediana
 es la semisuma de las frecuencias absolutas
es la semisuma de las frecuencias absolutas
 es la frecuencia absoluta de la clase mediana
es la frecuencia absoluta de la clase mediana
 es la frecuencia acumulada anterior a la clase mediana
es la frecuencia acumulada anterior a la clase mediana
 es la amplitud de la clase
es la amplitud de la clase
La mediana es independiente de las amplitudes de los intervalos
Ejemplo de cálculo de la mediana para distribución estadística
Calcular la mediana de una distribución estadística que viene dada por la siguiente tabla:
| |
|---|---|
 | |
 | |
 | |
 | |
 | |
En primer lugar crearemos una nueva columna con los valores de la frecuencia acumulada:
En la primera casilla colocamos la primera frecuencia absoluta. En la segunda casilla sumamos el valor de la frecuencia acumulada anterior más la frecuencia absoluta correspondiente y así sucesivamente hasta la última, que tiene que se igual a 
|  | |
|---|---|---|
| | |
| |  |
| | |
| | |
| | |
|
Buscamos el intervalo donde se encuentra la mediana, para ello dividimos la por porque la mediana es el valor central

Buscamos en la columna de las frecuencias acumuladas  el intervalo que contiene a
el intervalo que contiene a
Clase de la mediana:
Aplicaremos la fórmula para el cálculo de la mediana para datos agrupados, extrayendo los siguientes datos:





La media aritmética
Definición
La media aritmética es el valor obtenido al sumar todos los datos y dividir el resultado entre el número total de datos. Denotamos la media con el símbolo  y la calculamos de la siguiente manera
y la calculamos de la siguiente manera

en donde cada representa uno de nuestros datos y es el número total de datos que tenemos.
Ejemplo:
Los pesos de seis amigos son:  y
y  .
.
Hallar el peso medio.
Primero, notemos que tenemos seis datos, por lo tanto,  . Procedamos a calcular la media
. Procedamos a calcular la media

Media aritmética para datos agrupados
Cuando los datos vienen agrupados en una tabla de frecuencias, la expresión de la
media es distinta. Supongamos que tenemos  clases diferentes en nuestra tabla de frecuencias, en donde para cada clase
clases diferentes en nuestra tabla de frecuencias, en donde para cada clase  , tenemos su media y su frecuencia correspondiente, entonces calculamos la media como:
, tenemos su media y su frecuencia correspondiente, entonces calculamos la media como:

Debemos observar que ahora es la suma de las frecuencias de cada clase, esto es
 .
.
Además, cuando cada grupo o clase es un intervalo, la media de dicho intervalo es simplemente el punto medio entre los límites, así, suponiendo que un grupo es el intervalo  , entonces su media es
, entonces su media es  .
.
Como observación a considerar, notemos que al tener una tabla de frecuencias, al agrupar los datos, sustituimos cada dato por la media del grupo o clase al que pertenece, y que la suma de todas las frecuencias es igual a la cantidad de datos que tendríamos si no agrupáramos, por lo tanto, al calcular la media en datos agrupados, lo que hacemos es simplemente reemplazar cada dato por la media del grupo o clase al que pertenece. En caso de tener datos no agrupados, en general es mejor no agrupar ya que esto implica pérdida de información.
Ejercicio de media aritmética para datos agrupados
En un test realizado a un grupo de 42 personas se han obtenido las puntuaciones
que muestra la tabla.
Calcula la puntuación media.
| | |
|---|---|---|
| | |
| | |
 | | |
| | |
| | |
 | | |
| | |
Podemos observar como cada es punto medio del correspondiente intervalo.
Para obtener la media, en primer lugar, vamos a calcular la sumatoria de , crearemos una nueva columna para los productos de la variable con su correspondiente frecuencia absoluta y lo sumaremos todo. También tenemos que calcular que es la sumatoria de las frecuencias absolutas.
| |  | |
|---|---|---|---|
| | | |
| | |  |
| | |  |
| | |  |
| | |  |
| | |  |
| | |  |
| Sumas: | |  |
Entonces, utilizando nuestros datos, la media está dada por

Propiedades de la media aritmética
Primero, una definición que nos ayudará a entender mejor las definiciones. Sea  un conjunto de datos y la media de los datos, entonces, definimos la desviación de un dato, , respecto a la media como
un conjunto de datos y la media de los datos, entonces, definimos la desviación de un dato, , respecto a la media como
 .
.
1. La suma de las desviaciones de todos los datos de una distribución
respecto a la media de la misma igual a cero. Esto es

La suma de las desviaciones de los números  de su media aritmética
de su media aritmética  es igual a :
es igual a :

2. La suma de los cuadrados de las desviaciones de los valores de la variable con respecto a un número cualquiera se hace mínima cuando dicho número coincide con la media aritmética. En otras palabras, lo siguiente siempre se cumple

3. Si a todos los valores de la variable se les suma un mismo número, la media aritmética de estos nuevos datos es a la media de los anteriores más la misma cantidad que se le sumó a los datos. Esto es, suponiendo que tenemos los datos  con media , ahora, si le sumamos a todos los datos una cantidad
con media , ahora, si le sumamos a todos los datos una cantidad  ,
,  , la media de estos nuevos datos es
, la media de estos nuevos datos es

4. Si todos los valores de la variable se multiplican por un mismo número la media
aritmética queda multiplicada por dicho número. Esto es, suponiendo que tenemos los datos con media , ahora, si multiplicamos a todos los datos por una cantidad ,  , la media de estos nuevos datos es
, la media de estos nuevos datos es

Observaciones sobre la media aritmética
1. La media se puede hallar sólo para variables cuantitativas.
2. La media es independiente de las amplitudes de los intervalos.
3. La media es muy sensible a las puntuaciones extremas, también conocidos como valores atípicos. Si tenemos una distribución con los siguientes pesos:
 .
.
La media es igual a  , que es una medida de centralización poco representativa
, que es una medida de centralización poco representativa
de la distribución, sin embargo esto pasa porque tenemos un dato muy alejado a los demás,  .
.
4. La media no se puede calcular si hay un intervalo con una amplitud indeterminada.
| | |
|---|---|---|
|  | |
|  | |
|  | |
|  | |
 | | |
|
En este caso no es posible hallar la media porque no podemos calcular la marca de clase de último intervalo.
Cuartil
¿Que son los cuartiles?
Los cuartiles son una herramienta que usamos en la estadística y que nos sirve para administrar grupos de datos previamente ordenados.
Los cuartiles son los tres valores de la variable que dividen a un conjunto de datos ordenados en cuatro partes iguales.

 y
y  determinan los valores correspondientes al %, al % y al % de los datos.
determinan los valores correspondientes al %, al % y al % de los datos.  coincide con la mediana.
coincide con la mediana.
Cálculo de los cuartiles
1. Ordenamos los datos de menor a mayor.
2.Buscamos el lugar que ocupa cada cuartil mediante la expresión 
Número impar de datos


Número par de datos


Cálculo de los cuartiles para datos agrupados
En primer lugar buscamos la clase donde se encuentra , en la tabla de las frecuencias acumuladas.

es el límite inferior de la clase donde se encuentra el cuartil.
es la suma de las frecuencias absolutas.
es la frecuencia acumulada anterior a la clase del cuartil.
es la amplitud de la clase.
Ejemplo de ejercicio de cuartiles
Calcular los cuartiles de la distribución de la tabla:
| |
|---|---|
|  |
|  |
|  |
|  |
 | |
 |  |
 |  |
En primer lugar crearemos una nueva columna con los valores de la frecuencia acumulada:
En la primera casilla colocamos la primera frecuencia absoluta.
En la segunda casilla sumamos el valor de la frecuencia acumulada anterior más la frecuencia absoluta correspondiente y así sucesivamente hasta la última, que tiene que ser igual a 
 |  | |
|---|---|---|
 | | |
 | |  |
 | |  |
 | |  |
 | |  |
 | |  |
 | |  |
|
Cálculo del primer cuartil
Buscamos el intervalo donde se encuentra el primer cuartil, multiplicando  por
por  y dividiendo por
y dividiendo por  .
.

Buscamos en la columna de las frecuencias acumuladas  el intervalo que contiene a
el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de cuartiles para datos agrupados, extrayendo los siguientes datos:





Cálculo del segundo cuartil
Buscamos el intervalo donde se encuentra el segundo cuartil, multiplicando por  y dividiendo por .
y dividiendo por .

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a .
La clase de es:
Aplicaremos la fórmula para el cálculo de cuartiles para datos agrupados, extrayendo los siguientes datos:




Cálculo del tercer cuartil
Buscamos el intervalo donde se encuentra el tercer cuartil, multiplicando por y dividiendo por .

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a 
La clase de es:
Aplicaremos la fórmula para el cálculo de cuartiles para datos agrupados, extrayendo los siguientes datos:



Deciles
Definición de deciles
Los deciles son los nueve valores que dividen una serie de datos ordenados en diez partes iguales.
Los deciles dan los valores correspondientes al %, al %… y al  % de los datos.
% de los datos.
El quinto decil coincide con la mediana: . Pero también, coincide con el segundo cuartil:
. Pero también, coincide con el segundo cuartil: .
.
Cálculo de los deciles
En primer lugar buscamos la clase donde se encuentra  , en la tabla de las frecuencias acumuladas.
, en la tabla de las frecuencias acumuladas.

es el límite inferior de la clase donde se encuentra el decil i-ésimo.
es la suma de las frecuencias absolutas.
es la frecuencia acumulada anterior a la clase el decil i-ésimo.
es la amplitud de la clase o longitud del intervalo correspondiente a la clase del decil i-ésimo.
Ejercicio de deciles
Calcular los deciles de la distribución de la tabla.
| |
|---|---|
| |
| |
| |
|  |
| |
| |
| |
Solución:
En primer lugar crearemos una nueva columna con los valores de la frecuencia acumulada. Para obtener la frecuencia acumulada realizamos lo que se indica:
En la primera casilla colocamos la primera frecuencia absoluta. En la segunda casilla sumamos el valor de la frecuencia acumulada anterior más la frecuencia absoluta correspondiente y así sucesivamente hasta la última, que tiene que ser igual a  .
.
| | |
|---|---|---|
| | |
| | |
| | |
| | |
| |  |
| |  |
| | |
|
Cálculo del primer decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:





Cálculo del segundo decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a .
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:



Cálculo del tercer decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:



Cálculo del cuarto decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:

Cálculo del quinto decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:

Cálculo del sexto decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:




Cálculo del séptimo decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:

Cálculo del octavo decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:

Cálculo del noveno decil
Buscamos la clase donde se encuentra el primer decil:

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a  .
.
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de deciles para datos agrupados, extrayendo los siguientes datos:




Los percentiles
Definición de percentiles
Los percentiles son los  valores que dividen una serie de datos ordenados en partes iguales.
valores que dividen una serie de datos ordenados en partes iguales.
Los percentiles dan los valores correspondientes al  , al
, al  … y al
… y al 
de los datos.
 coincide con la mediana
coincide con la mediana
coincide con 
coincide con 

Cálculo de los percentiles
En primer lugar buscamos la clase donde se encuentra  , en la tabla de las frecuencias acumuladas.
, en la tabla de las frecuencias acumuladas.


es el límite inferior de la clase donde se encuentra el percentil
es la suma de las frecuencias absolutas
es la frecuencia acumulada anterior a la clase del percentil
es la amplitud de la clase
Ejercicio de percentiles
1 Calcular el percentil y  de la distribución de la tabla:
de la distribución de la tabla:

En primer lugar crearemos una nueva columna con los valores de la frecuencia acumulada:
En la primera casilla colocamos la primera frecuencia absoluta.
En la segunda casilla sumamos el valor de la frecuencia acumulada anterior más la frecuencia absoluta correspondiente y así sucesivamente hasta la última, que tiene que se igual a 

Cálculo del percentil 35
Buscamos el intervalo donde se encuentra el percentil , multiplicando por  y dividiendo por
y dividiendo por

Buscamos en la columna de las frecuencias acumuladas  el intervalo que contiene a
el intervalo que contiene a 
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de percentiles para datos agrupados, extrayendo los siguientes datos:





Cálculo del percentil 60
Buscamos el intervalo donde se encuentra el percentil , multiplicando por y dividiendo por

Buscamos en la columna de las frecuencias acumuladas el intervalo que contiene a
La clase de  es:
es:
Aplicaremos la fórmula para el cálculo de percentiles para datos agrupados, extrayendo los siguientes datos:




Desviación media
La desviación absoluta promedio o desviación media o también conocida como promedio de un conjunto de datos se puede definir como la media de las desviaciones absolutas
Desviación respecto a la media
La desviación respecto a la media es la diferencia en valor absoluto entre cada valor de la variable estadística y la media aritmética.

Desviación media
La desviación media es la media aritmética de los valores absolutos de las desviaciones respecto a la media y se representa por 


Ejemplo:
Calcular la desviación media de la distribución:

Calculamos la media aritmética para poder hallar las desviaciones respecto a la media

Aplicamos la fórmula de la desviación media

Desviación media para datos agrupados
Si los datos vienen agrupados en una tabla de frecuencias, la expresión de la desviación media es:


Ejemplo de calculo de desviación media para datos agrupados
Calcular la desviación media de la distribución:
| | |
 | | |
|---|---|---|
| | |
| | |
| | |
| | |
En primer lugar calculamos la media aritmética:
Incorporamos otra columna con los productos de las marcas de clase por sus frecuencias absolutas correspondientes y hacemos la suma 
Por otro lado realizamos la suma de las frecuencias absolutas 
| |  | |
| | | |
|---|---|---|---|
| | |  |
| | |  |
| | | |
| | | |
 |  |

Añadimos otra columna a la tabla con las desviaciones respecto a la media 
| | |  | |
| | | |  |
|---|---|---|---|---|
| | | |  |
| | | |  |
| | | |  |
| | | |  |
| |
Agregamos otra columna con los productos de desviaciones respecto a la media por sus frecuencias absolutas correspondientes  y hacemos la suma
y hacemos la suma 
| | | |  | |
| | | | |  |
|---|---|---|---|---|---|
| | | | |  |
| | | | |  |
| | | | |  |
| | | | |  |
| |  |
Calculamos la desviación media

Varianza
La varianza es la media aritmética del cuadrado de las desviaciones respecto a la media de una distribución estadística.
La varianza se representa por  .
.
La fórmula de la varianza


Ejemplos de cálculo de la varianza
1º Calcular la varianza de la distribución: 
Calculamos la media aritmética
Calculamos la varianza



2º Calcular la varianza de la distribución: 
Calculamos la media aritmética

Calculamos la varianza



3º Calcular la varianza de la distribución: 
Usando las mismas etapas como en los ejemplos anteriores, primero calculamos la media aritmética y luego la varianza.







4º Calcular la varianza de la distribución: 
Usando las mismas etapas como en los ejemplos anteriores, primero calculamos la media aritmética y luego la varianza.




5º Calcular la varianza de la distribución: 
Usando las mismas etapas como en los ejemplos anteriores, primero calculamos la media aritmética y luego la varianza.





Varianza para datos agrupados


Para simplificar el cálculo de la varianza vamos o utilizar las siguientes expresiones que son equivalentes a las anteriores.


Ejemplo de cálculo de datos agrupados
Calcular la varianza de la distribución de la tabla:
| |  |  | |
|---|---|---|---|---|
| | | |  |
| | | |  |
| | | |  |
| | | |  |
 | | | |  |
| | | |  |
| | | |  |
| |  |
Hemos añadido la columna porque queremos hallar su sumatoria  , que
, que
después dividiremos por  para obtener la media
para obtener la media

Hemos añadido la columna porque queremos hallar su sumatoria  , que después dividiremos por y al resultado le restaremos la media aritmética al cuadrado
, que después dividiremos por y al resultado le restaremos la media aritmética al cuadrado 
.

Propiedades de la varianza
1º La varianza será siempre un valor positivo o cero, en el caso de que las puntuaciones sean iguales.
2º Si a todos los valores de la variable se les suma un número la varianza no varía.
3º Si todos los valores de la variable se multiplican por un número la varianza queda multiplicada por el cuadrado de dicho número.
4º Si tenemos varias distribuciones con la misma media y conocemos sus respectivas varianzas se puede calcular la varianza total.
Si todas las muestras tienen el mismo tamaño:

Si las muestras tienen distinto tamaño:

Observaciones sobre la varianza
1º La varianza, al igual que la media, es un índice muy sensible a las puntuaciones extremas.
2º En los casos que no se pueda hallar la media tampoco será posible hallar la varianza.
3º La varianza no viene expresada en las mismas unidades que los datos, ya que las desviaciones están elevadas al cuadrado.
La desviación típica
La desviación típica es la raíz cuadrada de la varianza.
Es decir, la raíz cuadrada de la media de los cuadrados de las puntuaciones de desviación.
La desviación típica se representa por  .
.


Ejemplo
Calcular la desviación típica de la distribución:

Calculamos la media aritmética

Sustituimos en la fórmula de la desviación típica

Desviación típica para datos agrupados


Para simplificar el cálculo vamos o utilizar las siguientes expresiones que son equivalentes a las anteriores.




Ejemplo
Calcular la desviación típica de la distribución de la tabla:
 | |  |  | |
|---|---|---|---|---|
 | | | | |
 | | | |  |
| | | |  |
 | | | |  |
 | | | |  |
| | | |  |
 | | | |  |
|  |  |
Hemos añadido la columna porque queremos hallar su sumatoria  , que después dividiremos por
, que después dividiremos por  para obtener la media
para obtener la media

Hemos añadido la columna porque queremos hallar su sumatoria  , que después dividiremos por y al resultado le restaremos la media aritmética al cuadrado
, que después dividiremos por y al resultado le restaremos la media aritmética al cuadrado  , y por último haremos la raíz cuadrada del resultado obtenido
, y por último haremos la raíz cuadrada del resultado obtenido

Propiedades de la desviación típica
1º La desviación típica será siempre un valor positivo o cero, en el caso de que las puntuaciones sean iguales.
2º Si a todos los valores de la variable se les suma un número la desviación típica no varía.
3º Si todos los valores de la variable se multiplican por un número la desviación típica queda multiplicada por dicho número.
4º Si tenemos varias distribuciones con la misma media y conocemos sus respectivas desviaciones típicas se puede calcular la desviación típica total.
Si todas las muestras tienen el mismo tamaño:

Si las muestras tienen distinto tamaño:

Observaciones sobre la desviación típica
1º La desviación típica, al igual que la media y la varianza, es un índice muy sensible a las puntuaciones extremas.
2º En los casos que no se pueda hallar la media tampoco será posible hallar la desviación típica.
3º Cuanta más pequeña sea la desviación típica mayor será la concentración de datos alrededor de la media.
Coeficiente de variación y puntuaciones típicas
Coeficiente de variación
El coeficiente de variación es la relación entre la desviación típica de una muestra y su media.

El coeficiente de variación se suele expresar en porcentajes:

El coeficiente de variación permite comparar las dispersiones de dos distribuciones distintas, siempre que sus medias sean positivas.
Se calcula para cada una de las distribuciones y los valores que se obtienen se comparan entre sí.
La mayor dispersión corresponderá al valor del coeficiente de variación mayor.
Ejemplo:
Una distribución tiene  y
y  y otra
y otra  y
y  . ¿Cuál de las dos presenta mayor dispersión?
. ¿Cuál de las dos presenta mayor dispersión?


La primera distribución presenta mayor dispersión.
Puntuaciones típicas
Puntuaciones diferenciales
Las puntuaciones diferenciales resultan de restarles a las puntuaciones directas la media aritmética.

Puntuaciones típicas
Las puntuaciones típicas son el resultado de dividir las puntuaciones diferenciales entre la desviación típica. Este proceso se llama tipificación.
Las puntuaciones típicas se representan por  .
.

Observaciones sobre puntuaciones típicas
La media aritmética de las puntuaciones típicas es
La desviación típica de las puntuaciones típicas es
Las puntuaciones típicas son adimensionales, es decir, son independientes de las unidades utilizadas
Las puntuaciones típicas se utilizan para comparar las puntuaciones obtenidas en distintas distribuciones
Ejemplo:
En una clase hay alumnos y alumnas. El peso medio de los alumnos es  kg y el de las alumnas
kg y el de las alumnas  kg. Las desviaciones típicas de los dos grupos son, respectivamente,
kg. Las desviaciones típicas de los dos grupos son, respectivamente,  kg y
kg y  kg. El peso de José es de
kg. El peso de José es de  kg y el de Ana es kg. ¿Cuál de ellos puede, dentro del grupo de alumnos de su sexo, considerarse más grueso?
kg y el de Ana es kg. ¿Cuál de ellos puede, dentro del grupo de alumnos de su sexo, considerarse más grueso?


José es más grueso respecto de su grupo que Ana respecto al suyo.
